What Most Companies Get Wrong When Hiring SRE Teams (And What To Do Instead)

Hiring SRE teams looks straightforward on paper, but in reality, it’s anything but.
Site Reliability Engineers sit at the crossroads of software engineering, infrastructure, and operations, and getting that balance in their role wrong has real consequences.
This article breaks down:
Why hiring SREs is so complex
The common mistakes teams make
How organizations, especially with support from partners like Alpha Apex Group, can build sustainable, high-impact SRE teams
Let’s dive in.
What SRE Roles Look Like in Practice
The SRE role includes automating away repetitive operational tasks, leading incident response and blameless postmortems, defining and tracking reliability through SLIs and SLOs, and working closely with product and engineering teams to balance feature delivery with system stability.
SRE isn’t traditional operations with a new title, and it’s not just DevOps by another name. In practice, SREs apply software engineering principles to reliability problems to build systems that scale, fail gracefully, and recover quickly.
Take it from Google’s Ben Treynor, who coined the term Site Reliability Engineering:
“SRE is what happens when you ask a software engineer to design an operations team.” (Ben Treynor, SRE Basics: Site Reliability Engineering Explained)
That means real SRE work goes far beyond keeping the lights on.
One of the biggest reasons SRE hiring goes wrong is simple: the role is often misunderstood. As such, many job descriptions still focus on tools and reactive problem solving.
And the data shows why that’s a problem.
Median operational toil for SRE teams has increased recently to 20%, up from 14% in 2024, despite years of investment in automation.
This suggests that simply adding headcount, without the right role definition, doesn’t solve the underlying issues.
This mismatch is a major contributor to SRE burnout and failed hires.
Why Hiring SREs Is Inherently Difficult
When SRE hiring falls short, it’s tempting to blame slow recruiters or a weak interview process. But really, the challenge runs much deeper. The simple truth is that hiring SREs is structurally hard, even for well-resourced organizations.
Talent scarcity and market competition
SRE roles pull from multiple talent pools at once: software engineering, systems engineering, cloud infrastructure, and incident management. That overlap dramatically narrows the candidate pool, while demand continues to grow.
Unsurprisingly, competition is fierce. Seventy-six percent of technology hiring managers say recruiting technical talent is very or quite competitive, which shows just how saturated the market has become.
From a leadership perspective, the pressure is just as visible. Eighty-six percent of CIOs report increased competition for qualified tech candidates, which means SRE hiring is happening in an environment where speed, employer brand, and technical maturity all influence outcomes.
Skills gaps go beyond pure technical ability
Even when companies find technically strong candidates, another gap appears.
SREs need to:
Communicate clearly during incidents.
Make judgment calls under pressure.
Think in systems rather than silos.
Yet many hiring processes still place way too much importance on tools and certifications.
That focus is, of course, important, but to hire the best SREs, you need to zoom out and pay attention to soft skills and broader experience that goes beyond technical capabilities.
Role ambiguity inside organizations
Finally, many companies simply aren’t clear on what they need. Gartner research shows that only 8% of organizations have reliable data on the skills they currently have versus what they need, which explains why SRE hiring so often starts off misaligned from day one.
All these challenges come together to make SRE hiring unusually difficult, with competing demands, unclear definitions, and a constrained talent market.
Common Mistakes Companies Make When Hiring SRE Teams
When hiring SREs, a few common missteps tend to show up again and again. These mistakes usually come from misunderstanding what the role actually requires. We discuss them below, so you can be aware of them in your own hiring process.
Treating SRE like a plug-and-play ops role
A frequent mistake is expecting a new hire to immediately fix reliability. Without clear Service Level Objectives, ownership boundaries, or organizational support, this approach pushes SREs into constant firefighting instead of long-term reliability improvements.
Using generic interview processes
Standard software engineering interviews rarely test incident response thinking, systems trade-offs, or how candidates operate under pressure. Without role-specific assessments, teams run the risk of hiring candidates who interview well but aren’t actually prepared for SRE work.
Expecting one hire to fix reliability
Reliability is a team and organizational concern, not an individual one. This is especially risky given the stakes: 53% of organizations say poor system performance is just as damaging as complete downtime. This tells us that reliability failures are a direct business risk, not just an operational inconvenience.
These issues ultimately stem from unclear expectations. Fixing them starts with changing how organizations think about SRE roles in the first place.

How to Hire SRE Teams More Effectively (Actionable Framework)
Understanding the challenges around hiring SREs is important, but it’s still only half the battle. The real value comes from translating those insights into a hiring approach that actually works in practice.
Hiring SREs successfully means being intentional about reliability goals, about how you assess candidates, and about how you support them once they join. Here’s our framework for hiring SRE teams the right way.
Define what reliability means for your business
Before you post a role or interview a single candidate, you need to get clear on what “reliability” actually means in your organization. That starts with clearly defined SLOs, clear ownership across teams, and realistic expectations for what an SRE can influence in their first 90 days.
Without this clarity, even strong hires end up reacting instead of improving systems.
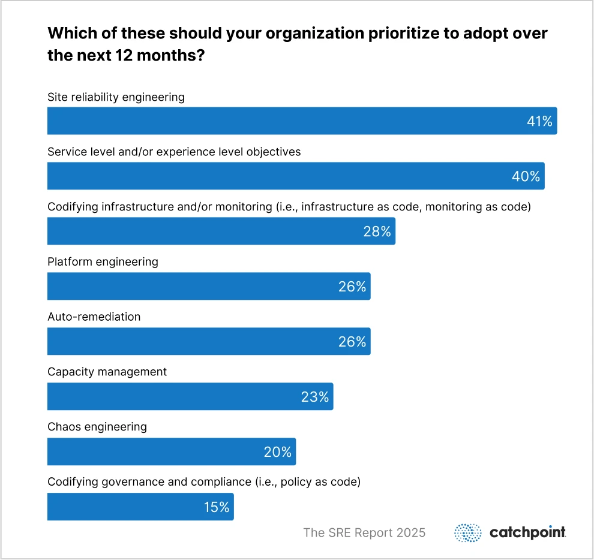
According to The SRE Report 2025, 41% of organizations identified site reliability engineering as their top priority when tracking performance indicators against service level objectives.
That’s a clear sign that reliability must be measured against explicit targets. If you haven’t defined those targets internally, hiring an SRE won’t fix the gap.
Hiring teams often skip this step, but it’s foundational.
Source: Catchpoint
Build a structured, role-specific hiring process
Once reliability goals are clear, the hiring process itself needs to reflect real SRE work. That means moving beyond generic interviews and focusing on how candidates think and operate under real-world conditions.
Effective SRE hiring processes should include scenario-based interviews, incident simulations, and cross-functional panels that involve engineering, product, and operations.
For example, instead of asking “Tell me about a time you handled an outage,” you might run a live scenario:
Scenario:

Follow-up prompts:
What signals would you check first?
How do you decide whether to roll back?
Who do you involve, and when?
What does good communication look like during this incident?
After recovery, what would your postmortem focus on?
This tests:
Systems thinking
Prioritization under ambiguity
Incident communication
Tradeoff awareness
Post-incident learning maturity
You can also simulate SLO decision-making:

This reveals whether they understand error budgets as decision tools.
This level of rigor is more necessary than ever in today’s tight talent market.
As we explained above, 76% of employers report difficulty filling roles due to a lack of skilled talent, which makes structured assessment one of the best ways to reduce mis-hires and improve long-term outcomes.
Onboarding and retention are part of hiring
Poor onboarding creates more work and more scope for things to go wrong, while strong onboarding creates momentum. Early wins, clear documentation, mentorship, and access to learning budgets all play a role in keeping SREs effective and engaged.
This is where organizations often underestimate the long game.
Partners like Alpha Apex Group help teams go beyond hiring by supporting structured onboarding, mentoring, and long-term SRE capability building. This way, new hires don’t just survive their first incidents, but grow into leaders who strengthen reliability over time.
Hire Better SRE Teams with AAG
Hiring SREs is a reflection of how mature an organization is in how it approaches reliability, ownership, and long-term resilience. Most of the hidden challenges in SRE hiring come from the fact that reliability can’t be outsourced to a single person or solved with a quick hire. It has to be built into the way teams work.
When organizations take the right approach, they’re rewarded with fewer outages, less operational work, reduced burnout, and stronger retention across engineering teams. When they get it wrong, even the most talented SREs struggle to make an impact.
At Alpha Apex Group, we work as a long-term partner to help companies tackle and solve the challenges associated with hiring SRE teams. From defining SRE roles and hiring frameworks to supporting onboarding, mentoring, and capability building, we help organizations move beyond reactive hiring and build SRE teams that scale with the business.
If you’re ready to hire smarter and build reliability into your organization for the long term, get in touch with us today.
FAQ
How many SREs per engineer should a company have?
There’s no fixed ratio, but many companies operate with 1 SRE for every 8-15 engineers. The right number depends on system complexity, uptime expectations, and automation maturity. If engineers spend more time reacting to issues than building, reliability capacity is likely under-resourced.
When should a company hire its first SRE?
Hire your first SRE when uptime of software impacts revenue, incident frequency rises, or reliability becomes a common challenge discussed at leadership level. If engineering teams rely heavily on tools like AWS CloudWatch but lack structured SLO ownership, it’s time to formalize reliability.
How long does it take to see impact from an SRE hire?
Initial improvements like clearer incident processes may appear within 30-60 days. Structural gains such as reduced toil, stronger automation, and measurable SLO improvements typically take 3-6 months, depending on system maturity and organizational alignment.
What are signs an SRE hire may fail?
Warning signs include undefined SLOs, unclear ownership, constant interrupt-driven work, and unrealistic expectations of immediate stability. Without executive support and clear reliability targets, even experienced SREs struggle to create sustainable impact.
What’s the difference between SRE and DevOps?
DevOps is a cultural model; SRE is an engineering implementation. Following the Google model, SRE applies software engineering to reliability using SLOs, automation, and operational monitoring. DevOps improves collaboration. SRE formalizes reliability controls within the tech stack.
Can consulting replace building an internal SRE team?
Consulting accelerates role definition, hiring frameworks, and reliability strategy. However, long-term resilience requires internal ownership. Many organizations combine both: external expertise to design the model and internal SREs to execute and evolve it.
Where should SRE report in an organization?
SRE typically reports into engineering, and not traditional IT operations. This keeps reliability aligned with system design and product delivery. When SRE sits outside engineering, the role can become reactive instead of influencing architecture and long-term technical decisions.
How important is tech stack experience when hiring SREs?
Tech stack familiarity matters, especially around cloud platforms, configuration management, and monitoring systems. However, strong candidates can adapt across a wide variety of environments. Systems thinking, automation ability, and reliability judgment often matter more than experience with one specific tool.
How do you assess cultural fit for SRE roles?
Cultural fit matters because SREs work across engineering, product, and leadership. Look for candidates who communicate clearly during incidents, handle pressure calmly, and support blameless postmortems. Reliability improves when collaboration across teams is strong, not siloed.




















