Avoiding Downtime: The Hiring Mistakes That Put Data Centers at Risk

Downtime can be disastrous for any data center, but the stakes are even higher for facilities providing cloud services, running mission-critical systems, or ensuring national security. And in many cases, the root cause is not technology failure, it’s people.
Yes, cyberattacks and external threats dominate headlines, but internal failures remain a major, under-discussed risk. According to the Uptime Institute, 40% of data center outages in the last three years were due to human error.
And the odds of such errors rise when you make hiring mistakes and recruit underqualified or undertrained workers.
In this article, we’ll go over how costly data center downtime can be and what companies owning and operating data centers can do to ensure it’s not caused by the people they hire.
P.S. Want to hire the best and the brightest of data center professionals? Alpha Apex Group connects you with experienced, vetted data center professionals who know how to protect uptime.
The True Cost of Data Center Downtime
Downtime is costly, we all know that. But that cost is both financial and reputational.
So, let’s talk about the financial damage first.
A widely cited figure from Gartner is $5,600, the cost per minute of an outage. However, that number is over a decade old. That has now been revised to $9,000 per minute.

But for some, the financial hit can be even higher.
In 2024, research shows that over 90 % of midsize and large firms report that an hour of unplanned downtime costs more than $300,000, and 41 % of enterprises say hourly downtime costs their organization $1 million to $5 million.
Beyond the loss of business, downtime can also lead to regulatory concerns, particularly if it is linked to a data breach. Regulated industries like healthcare and financial services may face prosecution and fines for non-availability of services, or, worse, a privacy breach.
Regulations like Europe’s GDPR or California’s CCPA require companies to protect user data, including data centers where it is housed and processed.
Ultimately, the true cost of downtime is a mix of lost revenue, increased risk, and weakened competitive position. For data center leaders and recruiting teams, this reinforces the fact that hiring talent with deep technical expertise, proper training, and a focus on reliability is essential.
How Hiring the Right People Is a Strategic Defense Against Downtime
Although downtime is not always caused by people working inside the data center, they can certainly play a pivotal role in preventing it or controlling it when it happens.
We see data center staff (technicians, engineers, architects, and analysts) as the first line of defense against downtime. Well‑chosen staff don’t just fix problems, they prevent them in the first place.
Skilled data center technicians, engineers, and facility managers bring both technical know‑how and situational intuition that can detect subtle anomalies in cloud environment performance, security policies adherence, or hardware health.
Here’s how smart hiring directly protects uptime and elevates operational reliability:
Rapid incident detection and response: Technicians with seasoned experience in server space, environmental systems, network engineering, and Artificial Intelligence (AI) can identify and resolve issues before they escalate into major outages. Quick, confident interventions reduce mean time to recovery (MTTR) and blunt the financial impact of downtime.
Risk‑aware decision making: When the professional understands the interplay between electrical distribution, cooling loads, and load‑balancing heuristics, they’re able to make decisions quickly for damage control when something goes wrong.
Cross‑functional awareness: Individuals who are eager to learn and evolve reduce skill gaps that sometimes lead to mishandling of complex systems.
Operators with strong staffing strategies reduce the frequency of outages and cut indirect costs associated with extended recovery efforts, customer notifications, and emergency support escalations.
In contrast, teams lacking experience or training are far more likely to misinterpret alerts, mishandle configurations, or delay escalation.
6 Common Data Center Hiring Mistakes That Increase Downtime Risk
A wrong hire can be costly to replace. However, in the case of hyperscale data centers (or any for that matter), financial loss can be even higher. No matter what role you’re filling, make sure you’re not making the mistakes below:
1. Hiring for Speed Instead of Skill
One of the most tempting shortcuts in the current data center labor market is to hire quickly, just to fill seats.
With labor shortages so acute that experienced technicians now command 15-25 % higher salaries than two years ago and engineers receive multiple offers within days, the pressure to move fast is real.
But prioritizing speed over skill can dramatically increase your risk of downtime and undermine your long‑term reliability strategy.
In many facilities, open roles remain unfilled for months because the talent pool simply can’t keep up with demand. This, naturally, leads some organizations to rush offers and onboard candidates without rigorous vetting.
Remember that speed is crucial, but it shouldn’t trump necessary checks for skill and compatibility, as well as training.
It’s important to vet the candidates for the specific role through interviews and practical tests, especially for more technical on-site roles. That’s because if the candidate isn’t suitable or lacks proper training, they might make mistakes that ultimately cause disruptions to operations.
Our take: While we pride ourselves on speed (average time to fill of 43 days, 60% higher than the national average), we also understand the gravity of data center operations. That’s why we have designed systems that help us find and shortlist candidates quickly, so most of the time can be used to assess their skills.
2. Undefined or Generic Job Roles
In a data center environment that supports everything from cloud computing and AI applications to enterprise cybersecurity operations, clarity matters.
When job descriptions are vague or generic, hiring teams struggle to match the right skills to the tasks that actually keep systems running. Also, downstream teams don’t know who owns what when things go wrong.
A data center typically depends on a diverse set of roles, from data center technicians and network engineers to facilities managers and operations leads. Each role should have clearly defined responsibilities for monitoring servers, power systems, environmental controls, and security posture.
When a job title like “IT support” is used without specifics about which systems, tools, or security policies that person will manage, the risk increases. Critical responsibilities can fall through the cracks or be duplicated, which leads to confusion and operational gaps.
Here’s an example of what a well-defined data center role looks like:

3. Ignoring Shift Coverage and 24/7 Realities
When you’re building a data center team for a facility that runs 24/7, you have to take into account coverage. Of course, personnel have to be there every minute of every day, which means workers might need to work nights and do overtime.
Historical operational data from Uptime Institute’s Abnormal Incident Reports shows that roughly 44 % of abnormal incidents occur between midnight and 8 a.m., and incidents are spread evenly across all days of the week.
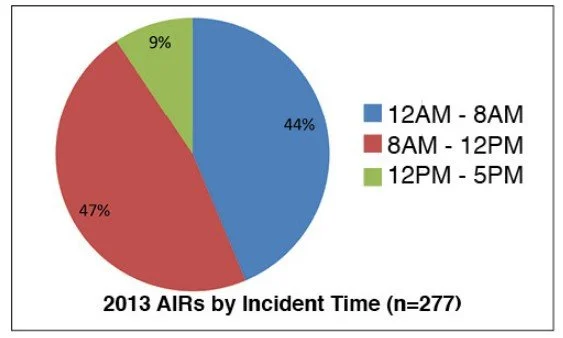
Image Source: Uptime Institute Journal
Failing to align your workforce with the continuous demands of data center operations is more than a scheduling oversight. In fact, it’s a vulnerability.
When shifts leave gaps in coverage or rely heavily on remote monitoring without qualified personnel on site, critical issues such as power irregularities, cooling system alarms, or hardware failures can go unnoticed until they trigger service degradation or outages.
For example, Microsoft’s Azure suffered a 46‑hour outage partly due to the cascading effects of infrastructure failure. In the aftermath, the company increased the number of nighttime staff to manually resolve issues if needed. This shows how slow responses can amplify impact in real‑world scenarios.
Moreover, the shift design itself is incredibly important. Extended shifts without adequate rest increase fatigue‑related risks, and that may lead to error‑prone decisions during peak stress moments.
4. Overlooking Soft Skills and Incident Response Ability
We have observed that data center roles that require real‑time incident response depend just as much on soft skills like clear communication, decisive problem‑solving, and teamwork.
If these interpersonal strengths are missing, even talented technicians may flounder when an urgent alert flashes red on the dashboards.
As recruiting specialists, we can assure you that soft skills are the difference between a calm, coordinated response and a chaotic escalation that prolongs downtime.
For example, effective communication ensures that a technician dealing with a hardware failure can quickly and clearly convey the issue to remote teams or vendors.
The speed of thinking and clarity of communication can help reduce the time it takes to resolve outages and minimize service disruptions. Conversely, poor communication can lead to misunderstandings that cascade into bigger problems.
That’s why we take a weighted approach in evaluating data center staff, particularly technicians and security specialists, and give soft skills their due importance. Interviews and scenario-based testing can help you gauge who has the soft skills to function well under pressure and who does not.
5. Training Gaps
Even the most advanced data centers can’t deliver reliable uptime without well‑trained people who understand both the technology and the operational discipline to execute consistently.
The need for training is even greater now, given the talent shortage and rising demand, in part due to the expansion of generative AI. Facilities may need to hire fresh talent from schools or even those without a formal college degree and train them internally to fill positions.
And we’ve established time and again that many outages are caused by human errors. It goes without saying that comprehensive, continuous training is key to ensuring errors don’t cause downtime.
“To avoid any downtime by human error, make sure your team is well-trained. Have a contingency plan in place to prepare your team for any type of scenario. Practice drills and role playing with your staff is a great method to ensure they will know how to react during data center downtime.” (Rich Banta of Lifeline Data Centers)
Here are practical tips about training data center staff that result in a dependable team:
Invest in certification programs and scenario simulations, so staff know what to do and how to apply that knowledge under real operational stress.
Don’t rely on certification credits or classroom hours alone; cultivate competency through hands-on exercises in the facility.
Provide vendor-agnostic training when working in a multi-vendor environment, so technicians and engineers are limited by what they know about a specific OEM.
Schedule periodic refresher courses, particularly when new protocols are rolled out or new equipment is installed, to ensure continuous learning.
6. The Experience Trap: Junior vs Senior Talent Imbalance
Unfortunately, many organizations fall into the experience trap: over‑relying on junior talent or accelerating promotions without the depth of practical operational know‑how that seasoned professionals bring.
Industry data shows significant staffing challenges at both ends of the experience spectrum. Roughly 58% of operators report difficulties finding qualified candidates, with many struggling to retain experienced staff while addressing shortages in junior and mid‑level roles.
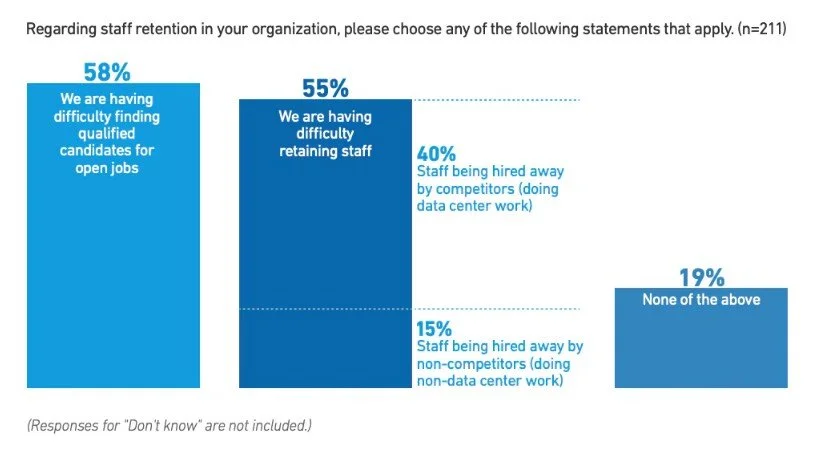
This creates a gap in which too many responsibilities fall to less-seasoned technicians, increasing the risk of human error and delayed responses during critical events.
A talent imbalance also stems from broader market pressures. Organizations may end up promoting junior staff into senior positions before they’ve fully mastered core capabilities. This trend can dilute institutional knowledge and weaken operational rigor when uptime matters most.
Why does this matter for downtime? Senior professionals excel at risk anticipation, interpreting complex systems under stress, and mentoring others during incidents. In contrast, less experienced staff may struggle with unexpected failures.
Without a balanced mix of experience, teams lack the layered judgment needed to mitigate cascading failures that lead to costly downtime. Again, training is crucial for this imbalance. If you need more senior staff amidst a shortage, it’s important to train junior staff before promoting them.
Pro Tip: Always have a senior technician or engineer present on-site to ensure their expertise is available to mitigate risks and handle incidents promptly.

How to Build a Data Center Hiring Strategy That Protects Uptime
We highly recommend having a concrete, repeatable hiring strategy grounded in the reality of running data centers. When we work with clients, we take a structured approach to defining roles, searching for the right talent, and, most importantly, training them so internal risks are minimized.
Now let’s explore how to architect a hiring strategy that strengthens resilience against downtime and elevates your team’s capability:
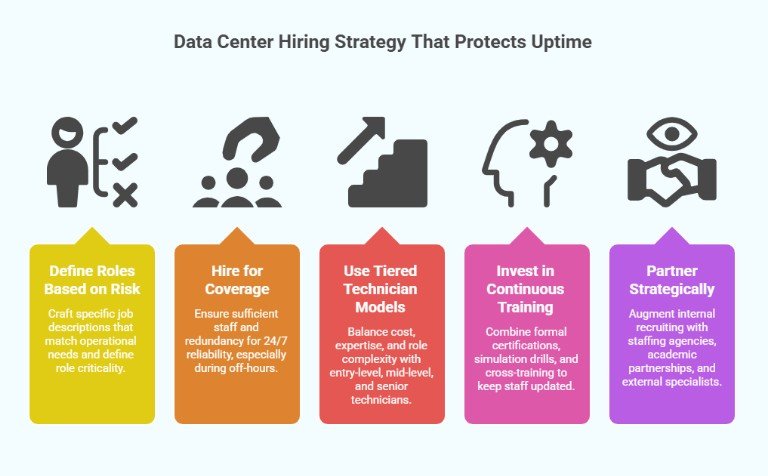
1. Define Roles Based on Risk
One of the most strategic steps in protecting uptime is crafting specific, risk‑aligned job descriptions that match real operational needs. That’s how you attract the right candidate, screen them for the work they’ll actually do, and also avoid employee misclassification.
Instead of generic titles like “IT support,” define roles with clear expectations for managing cybersecurity, security policies, data security, and performance tools like dashboards. Also, define the role's criticality.
When roles are aligned with risk (e.g., critical vs. non‑critical tasks), you avoid coverage gaps that lead to outages and ensure accountability during high‑pressure scenarios.
Example: A “Critical Systems Network Engineer” role should specify expectations for cloud computing stacks, data analytics monitoring, and incident triage protocols.
2. Hire for Coverage, Instead of Just Capability
To deliver true 24/7 reliability, hiring must account for coverage. This means ensuring you have sufficient boots on the ground, cross‑shift backups, and redundancy among team members on nights, weekends, and holidays.
Considering the industry trend toward hybrid operations with remote access and on‑site responses, identify who will take the first action on incidents in advance.
There should be a clear line of communication and hierarchy of responsibilities, so incidents can be handled promptly.
Practical tip: Use scheduling optimization tools and workforce analytics software to model optimal coverage and identify vulnerable gaps before they cause trouble.
3. Use Tiered Technician Models
Rather than treating all technicians as equal, adopt a tiered technician model to balance cost, expertise, and role complexity. For example:
Tier 1: Entry‑level technicians handle routine monitoring and standard operational checks.
Tier 2: Mid‑level personnel troubleshoot common issues and manage escalations.
Tier 3: Senior professionals carry out complex incident response, cross‑system integrations, and mentor junior staff.
This way, you preserve your talent pool by giving people clear progression paths. It also ensures that senior experts are not overloaded with routine tasks when uptime hangs in the balance.
Check out our detailed guide on hiring data center technicians for more details on tiers and where to find them.
4. Invest in Continuous Training and Simulation
Remember that you can’t avoid downtime if your people are unfamiliar with evolving technologies, such as AI-driven workloads, advanced cooling systems like liquid cooling, or hybrid IT architectures.
The industry is already wrestling with profound training gaps, and operators are underinvesting in long‑term development programs that help staff keep pace with innovation. On top of that, data center workers are switching careers, exacerbating the talent shortage.
And research confirms that companies that invest in employee development are twice as likely to retain employees and see 11% more profitability.
We suggest adopting a training framework that combines:
Formal certification programs (e.g., vendor‑specific technical accreditations like Cisco certifications if you use their hardware)
Hands‑on simulation drills that test responses to real‑world failures
Cross‑training between roles (e.g., pairing cybersecurity with physical infrastructure)
5. Partner Strategically for Hard-to-Find Skills
Given the ongoing data center workforce shortages, which are expected to require hundreds of thousands of additional trained professionals, it may not be the best idea to rely solely on internal recruiting.
Consider strategic partnerships that augment your hiring strategy:
Staffing agencies with large networks and customized training programs that deliver vetted technicians trained to your specific environment.
Academic partnerships with universities and vocational programs that pipeline students into internships and apprenticeships.
External specialists for niche skills like advanced cloud security or AI workloads.
These partnerships will help expand your available talent pools, speed up time‑to‑hire, and inject fresh competencies into your operations team.
Hire Reliable Data Center Staff with Alpha Apex Group
When your data center depends on every minute of uptime, partnering with a strategic recruitment firm can be the difference between reactive hiring and proactive resilience.
Alpha Apex Group is a consulting and recruitment firm that helps you accelerate access to high‑caliber talent with a structured, candidate‑focused recruiting process designed with built-in talent risk management.
With our proprietary tools and network of talent, we can deliver promising candidates in 72 hours. And from there, the process of background checks, interviews, and technical assessments begins (in which we can be heavily involved to streamline things).
Our recruiting services include executive search, high‑volume staffing, and end‑to‑end talent acquisition that reaches beyond traditional job boards.
Contact us to avoid making common data center hiring mistakes.
FAQs
What is the biggest hiring challenge for data centers?
The biggest challenge in data center recruitment is finding candidates with both the technical expertise and the operational discipline required to support 24/7 uptime. Also, there’s an acute shortage of technicians and engineers while the number of data centers is increasing.
How to screen and vet data center technicians for experience?
Effective screening of data center candidates includes scenario-based interviews, certification validation, and simulation drills that test candidates' responses to real‑time alerts and failures. Our recruitment experts at Alpha Apex Group can help you define screening and vetting procedures specific to the roles you’re filling to ensure a dependable hire.
How much can a bad hire cost a data center?
A bad hire can result in missed alerts, configuration errors, or poor incident response, all of which contribute to downtime. With average costs ranging from $300,000 to $5 million per hour of downtime, even one mistake can have a major financial and reputational impact.
How does Alpha Apex Group ensure compatibility when screening candidates?
At Alpha Apex Group, we combine predictive hiring analytics with behavioral screening (candidate psychology) and technical vetting to ensure alignment with both the role and organizational culture. We go beyond resumes to assess candidate performance in 24/7 operations, familiarity with security service, and adaptability to high-risk, high-uptime environments.
Is training necessary for new data center staff?
Absolutely. Research shows that many data center outages stem from failures to follow process or improper execution, both of which are preventable with proper training. This includes onboarding simulations, real-time scenario testing, and ongoing education on new technologies and equipment.