How to Build a Data Center Workforce for 24/7 Operations: A Hiring Playbook

Building and operating data centers that truly run 24/7 is a huge undertaking. Although it’s the servers, storage, and other equipment that dominate these facilities, they also require manpower to ensure smooth running round-the-clock.
And the vast majority of data centers run 24/7. That raises the bar for ensuring near-perfect uptime and availability.
The number of data centers has been increasing over the last few years and will continue to do so due to the Artificial Intelligence (AI) boom. But, at the same time, there’s a shortage of skilled data center talent, too.
Back in 2020, the Uptime Institute projected data center staffing to grow from about 2 million full-time equivalents in 2019 to nearly 2.3 million by 2025. And now with so many AI data centers planned or under construction, that number will only increase.
If you’re the leader overseeing an upcoming data center project or currently running one, you need a blueprint for creating a workforce that supports 24/7 operations. And that’s what this guide from Alpha Apex Group is all about.
What 24/7 Really Means in Data Centers?
When we talk about running data centers 24/7, we’re referring to high-availability infrastructure and mission-critical operations in a customer-facing environment that deliver continual service to customers around the world.
In other words, minimal downtime with resilient servers, cooling systems, power distribution, Uninterruptible Power Supplies (UPS), and network connectivity.
From an operational vantage point, 24/7 means building for high availability and resilience such that your facility continues to function through routine maintenance, equipment failures, and unpredictable events.
That expectation is formalized in industry standards like the Uptime Institute Tier Standard, the most widely adopted system for classifying data center reliability and redundancy.
Tier Levels and Redundancy: The Benchmarks for 24/7 Availability

The Tier system classifies data centers into four levels (Tier I through Tier IV), each with defining characteristics around redundancy, fault tolerance, and uptime guarantees.
Tier I: Provides basic capacity with a single power and cooling path and no required redundancy. The expected uptime is 99.671%, with a potential of up to 28.8 hours of downtime per year. This is acceptable for low-risk workloads but not typical for always-on operations.
Tier II: Adds redundant components (such as UPS modules and backup generators), which raise uptime to 99.741% (roughly 22 hours of downtime per year). There’s still a single distribution path for power and cooling, so planned maintenance may still impact operations.
Tier III: Introduces concurrent maintainability with multiple distribution paths and N+1 redundancy for critical systems. It allows maintenance without downtime. The uptime target jumps to 99.982%, or approximately 1.6 hours of downtime per year, which is aligned with expectations for modern cloud, colocation, and enterprise facilities.
Tier IV: Offers fault-tolerant architecture with 2N or 2N+1 redundancy, meaning every critical component (power, cooling, connectivity) is duplicated and independently distributed. This design supports 99.995% uptime (less than 26.3 minutes of downtime per year) and is typical for hyperscale data centers, financial, and healthcare environments where every minute counts.
The Tier levels signal the engineering and data center design expected for different service levels and implicitly guide the workforce planning and site selection decisions.
Higher-Tier facilities demand more skilled technicians who can manage redundant hardware and software, complex fire suppression systems, energy systems, and steel-tight documentation for regulatory and customer audits.
At the heart of 24/7 readiness is redundancy, duplicating critical pathways so that no single component failure takes down services. This includes strategies such as N+1 redundancy, in which an extra unit exists for every critical component (for example, electrical UPS complexes or cooling systems), and 2N and 2N+1 redundancy, in which complete dual systems operate in parallel.
What Are the Critical Roles for 24/7 Data Center Operations?
To sustain true 24/7 operations in modern data centers, you need the right mix of roles, with the right authority and skills, available at the right time.
As servers, storage systems, cooling systems, and power distribution architectures grow more complex (especially in hyperscale and AI-ready environments), staffing models must reflect how failures actually occur in a mission-critical environment.
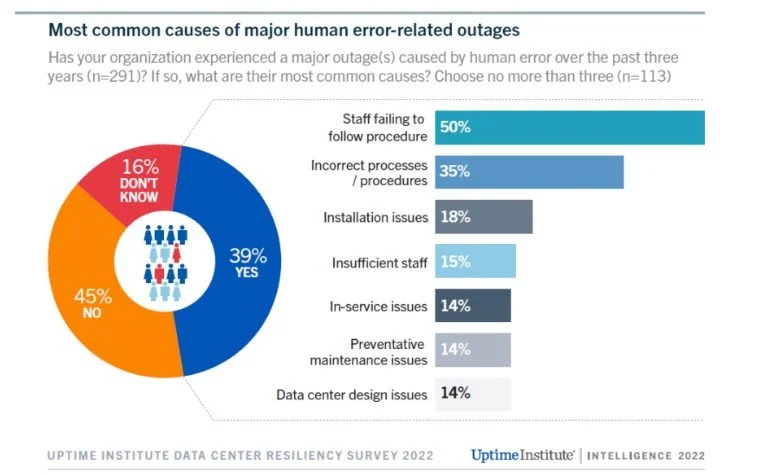
Our takeaway as a recruiting specialist has been that hiring the wrong person or not having enough personnel is a recipe for disaster. In fact, most outages are human-caused, as shown in the figure below.
Below, we break down the core role categories every always-on facility must account for, following the realities of operations rather than org charts.
On-Site Data Center Technicians
On-site technicians are the backbone of 24/7 operations. These roles directly touch physical hardware, server racks, electrical equipment, and life-safety systems, and they might also be the first responders when something goes wrong.
Core on-site roles usually include:
Critical Facilities Technicians (CFTs) are responsible for UPS systems, generators, redundant power paths, cooling systems, and fire suppression systems
IT / Data Center Technicians handle servers, hard disk drives, solid-state drives, cable management, and break-fix work.
Security staff manage physical security, biometric access controls, visitor logs, and coordination with emergency services.
In our experience, most Tier III and Tier IV facilities staff at least 2 to 4 on-site technicians per shift, depending on facility size (measured in megawatts) and redundancy level.
Data Center Engineers
While technicians keep the facility running minute-to-minute, engineers ensure it runs predictably, efficiently, and safely over time. In 24/7 operations, engineering coverage doesn’t always mean being physically on site every hour. However, they’re still important for guaranteed availability and clear escalation paths.
Key engineering roles include:
Electrical and Mechanical Engineers oversee power distribution, electrical switchgear, electrical UPS complexes, and hybrid or liquid cooling architectures.
Data Center Infrastructure Engineers focus on data center design, redundancy models, and energy efficiency.
Network and Systems Engineers support fiber-optic connectivity, fiber routes, virtualization, and network connectivity in carrier-neutral data centers.
In hyperscale data center environments, engineers may support multiple data center campuses remotely, but with strict on-call response times.
Google has publicly shared its Site Reliability Engineering (SRE) model that relies on tight engineer-to-system ratios and rigorous on-call rotations to meet aggressive availability targets.
Remote and Support Functions
24/7 operations don’t rely solely on who is physically inside the building. Remote and support roles extend visibility, speed, and resilience, especially as facilities scale.
These functions may include:
Network Operations Center (NOC) analysts provide real-time monitoring of data center infrastructure, alarms, and power reliability
Remote hands or smart hands teams execute guided physical tasks when senior staff are off-site.
IT support and monitoring teams oversee software, storage systems, and automation platforms tied to AI-driven data centers.
Side note: The Top Data Center Recruitment Agencies can help you fill all these roles with qualified professionals.
Shift Design and Workforce Modeling
Besides recruiting an ample and competent team for your data center, designing and implementing shift schedules is crucial for 24/7 data campuses.
And designing 24/7 shift schedules for data centers shouldn’t be about filling hours on a calendar. The goal should be to create patterns that maintain total coverage, support security and operational goals, and reduce burnout across teams.
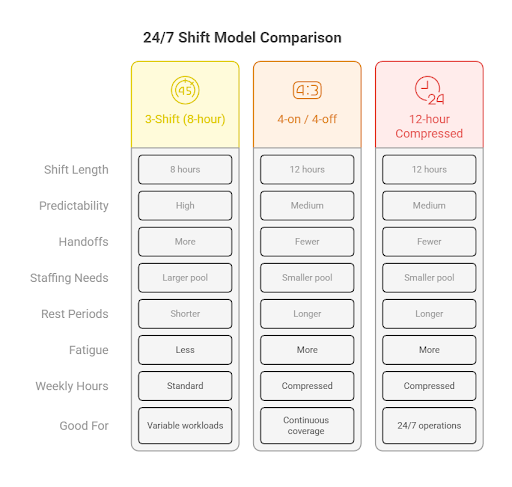
In workforce planning for mission-critical environment operations, common 24/7 patterns include classic 3-shift rotations, 4-on/4-off blocks, and compressed 12-hour shifts, each with tradeoffs in staffing needs, fatigue risk, and workforce satisfaction.
Common 24/7 Shift Models
Here’s a comparison of commonly used shift models inside data centers:
3-shift (8-hour) rotation
The 3-shift model, where day, evening, and night shifts each cover 8 hours, is the most straightforward approach to round-the-clock coverage. This model divides the 24 hours into three equal parts, so that servers, security staff, and operational functions are staffed continuously.
Pros
Predictable 8-hour work blocks help avoid employee fatigue and align with conventional labor standards.
Less pronounced circadian disruption compared with 12-hour shifts.
Cons
More handoffs between shifts, which can increase the risk of communication errors unless strict documentation discipline and handoff tools are in place.
Requires a larger pool of staff to cover transitions and overlap zones.
Good for
For facilities with highly variable workloads, such as hyperscale data center campuses supporting AI workloads, heavy cloud computing, or High-Performance Computing.
4-on / 4-off
In the 4-on/4-off pattern, workers typically operate 12-hour shifts, for example, four consecutive days with 12-hour coverage, followed by four days off, and then cycle between day and night blocks. This creates a simple, repeatable rhythm that aligns well with continuous 24/7 operations.
Pros
Extended rest periods (four days off) help recovery and reduce turnover.
Fewer shift handoffs reduce operational risk.
Cons
Extended 12-hour demands raise fatigue considerations, especially overnight.
Can compress weekly hours into higher weekly totals.
Good for
This pattern is widely used in industries that require continuous coverage, such as critical infrastructure and emergency services.
12-hour compressed shifts
Compressed 12-hour patterns include variations such as 3-on/4-off rotations (three 12-hour days followed by four days off), which offer long rest periods and comparatively stable weekly schedules. The classic 3-on/4-off cycle is used across multiple 24/7 sectors.
Pros
Long off periods improve morale and work–life balance.
For roles like remote hands or overnight electricians, sustained blocks help with continuity and planning.
Cons
Extended shifts can reduce alertness late in the day if not carefully managed.
Needs careful headcount modeling to ensure coverage doesn’t dip due to overlapping off-blocks.
Good for
All of these patterns are variants of shift work, a practice specifically designed to ensure 24-hour coverage, 7 days per week, in operations where continuity matters. However, they must be evaluated not just for coverage but also for workforce health and operational risk.
How to Calculate Minimum Safe Headcount
Once a shift model is selected, you need to translate it into the minimum safe staffing levels required to avoid gaps in your data center operations.
True staffing math starts with coverage needs (in a realistic lens). For an 8-hour 3-shift model, basic coverage alone means:
3 shifts/day × 7 days = 21 shift slots/week.
Similarly, a 12-hour 4-on/4-off schedule might mean:
One team covers 12-hour days for four days, gets four off, and alternates with at least one other team to cover nights, requiring a minimum of 4 full-time equivalents per role just to cover the baseline pattern.
Pro Tip: Across any model, ensure that headcount goals include at least 1.2–1.4× multipliers on baseline counts to account for variability. Otherwise, you risk gaps when real-world conditions hit.
Accounting for PTO, sick leave, and attrition:
Although many workers don’t use all of their PTO or paid time off (46% according to a Pew Research survey), you have to plan as if they do use all of it. In fact, it’s better to plan for more than the stipulated paid time off and/or sick days, especially for an employer like a data center.
Furthermore, attrition can erode your baseline numbers if not anticipated. There’s already a very high rate of turnover in data center jobs, with 40% of workers planning to change jobs.
Now, retention is a whole different topic, but as far as planning staffing needs go, attrition should be taken into account, and a contingency plan should be in place (like smart hands or temporary contractual hires).
Pro Tip: We highly recommend retention programs, such as workforce training initiatives, to keep staff engaged and minimize turnover.
Hiring Profiles for 24/7 Data Center Roles
To staff 24/7 operations in a mission-critical environment, your hiring playbook must go beyond job titles and clearly define the skills and traits that enable individuals to run data centers reliably.
In our experience working with multiple data center teams, the strongest operations are built around role clarity, operational readiness, and decision-making ability under pressure.
The section below breaks down the essential capabilities for core roles and explains how skills must align with real-world operational needs.
Skills for Core Data Center Roles
Across on-site technicians, engineers, and remote support functions, certain competencies are table stakes in 24/7 operations.
Technical Proficiency
At the core, every role requires a strong foundation in the physical and logical systems that keep data centers running:
Hardware & server knowledge: Technicians should be adept at installing, racking, and maintaining servers, including hard disk drives (HDDs), solid-state drives (SSDs), server racks, and peripheral hardware. They must also be able to diagnose and resolve hardware failures quickly and accurately under pressure.
Network and power fundamentals: Understanding network connectivity, TCP/IP basics, cabling (including fiber-optic routes), and basic power reliability principles is crucial for rapid troubleshooting.
Environmental systems: Day-to-day operation includes monitoring and responding to alarms from cooling systems, HVAC, total energy infrastructure, and UPS systems — meaning familiarity with Uninterruptible Power Supplies and environmental sensors is essential.
From what we’ve seen, exact technical skill requirements should always be defined by what the role actually needs to handle during live operations. Skill depth should match real responsibilities, escalation expectations, and shift coverage realities.
Documentation, Tools, and Process Discipline
In data centers, a thorough and standardized documentation discipline goes a long way. Candidates must be comfortable using DCIM (Data Center Infrastructure Management) tools, ticketing systems, and checklists to log work, escalate issues, and execute repeatable procedures without ambiguity.
That’s why we strongly emphasize these soft skills when searching for data center talent, regardless of role. The ability to follow runbooks, update tickets in real time, and document actions clearly is essential in always-on environments.
Strong documentation supports runbooks and audits (including HIPAA Disclosure requirements or geographic regulatory frameworks). It also forms the backbone of successful shift handoffs.
Security Awareness
In a 24/7 data center environment, security awareness is a baseline requirement for every role.
All team members must understand physical security protocols and biometric access controls. Entry-level candidates should be trained in role-based access tiering and security policies as part of onboarding
This early reinforcement of security best practices protects both people and infrastructure from insider risks and unauthorized access.
Skills That Matter Most on Night and Weekend Shifts
Some skills and qualities are particularly important for staff covering night and weekend shifts, when support resources are limited, and response windows are tighter.
Independent troubleshooting: When alerts from UPS systems, power grids, or fire detection/suppression systems occur after hours, workers should be able to troubleshoot issues themselves before escalating them to engineers.
Incident judgment under pressure: High stakes in Tier III or Tier IV Gold facilities demand quick thinking. Night shift technicians must make sound decisions about containment, escalation, and contingency execution.
Communication and Collaboration: Effective verbal and written communication is essential for conveying status updates, clarifying incidents, and ensuring continuity across handoffs.
Pro Tip: Based on our experience, hiring assessments are most effective when they include scenario-based simulations that reflect common night-shift and weekend incidents. This approach reveals how candidates think, document, and escalate under real operational pressure.
Experience vs. Trainability Trade-Offs
Experienced candidates bring immediate value, especially in complex systems. These hires may justify higher wages but can reduce onboarding time and early risk.
On the other hand, trainable candidates, such as those transitioning from related fields (electricians, military technical veterans, or networking specialists), can grow into roles where advanced skills like virtualization, cloud computing, and AI Analytics management become valuable.
In our experience, pairing these hires with mentorship and structured learning accelerates readiness and helps address the shortage of skilled labor.
And how do you balance junior and senior roles?
Junior technicians are invaluable for executing tactical tasks, such as racking equipment, conducting visual inspections, overseeing preventive maintenance, and handling well-documented tasks. However, senior coverage should be guaranteed for shifts when critical decisions could affect recovery time objectives (RTOs).
In facilities with demanding uptime commitments, a senior technician or engineer must be available (either on site or on call) to oversee responses that extend beyond routine maintenance.
Build a Pipeline for Data Center Talent to Maintain 24/7 Operations
Sustaining 24/7 operations in modern data centers requires a repeatable talent pipeline that accounts for labor shortages, rising IT spending, increasing AI workloads, and operational complexity.
We have noticed that as facilities grow in megawatt capacity and even gigawatt-scale data center campuses come about, workforce continuity becomes as critical as power reliability or redundant power paths.
Without a steady pipeline of qualified talent, even the most technically resilient facilities face operational risk.
Where to Source 24/7-Ready Talent
The following talent sources have proven most effective for sustaining 24/7 data center operations:
Contract staffing pools: Contract and contingent labor remain a critical pressure valve for 24/7 operations, particularly during expansions, construction, and unplanned attrition. These are temporary contractual hires who help fill in gaps (usually provided by staffing agencies).
Military and technical veterans: One of the most reliable and underutilized pipelines for 24/7 data center roles is veterans with a technical background. Programs connected to Veteran Resource Centers and Department of Defense SkillBridge initiatives allow operators to onboard transitioning service members. If you have the capacity to provide training, this can be a great option.
Career-path technicians: Long-term resilience comes from developing technicians who see data centers as a career. That means hiring technicians, engineers, and security specialists who have been trained and have worked in data centers. Such candidates typically also have certifications.
Work with a Data Center Recruiter
Specialized recruiters who understand digital infrastructure and hyperscale data center operations can materially improve hiring outcomes.
A data center-focused recruiter like Alpha Apex Group brings:
Pre-screened candidates familiar with 24/7 shift work.
Access to passive talent pools unavailable through general job boards.
Market intelligence on wages, union vs. non-union labor (like union electricians), and regional availability.
Recruiters embedded in the sector can also advise on geographic dynamics tied to site selection, energy infrastructure, and regional supply chain issues.
For instance, in addition to covering staffing needs, we also work in a consultancy capacity for enterprises with data centers, especially those investing in AI.
Security, Access, and Compliance in Hiring
In 24/7 data centers, hiring decisions directly affect physical and operational risk. Because technicians, engineers, and security staff have unsupervised access to infrastructure during nights and weekends, security screening and access governance must be embedded into the hiring process from day one.
Role-appropriate background checks, employment verification, and regulatory screenings are a must.
At Alpha Apex Group, we conduct extensive screening of shortlisted applicants to ensure they meet both job and compliance requirements, particularly in industries like healthcare and finance.
Equally important is access tiering. Mature operators align permissions to role, shift, and task scope, using controls such as biometric access controls and time-bound credentials to limit exposure without slowing incident response.
Junior technicians, contractors, and remote hands should never have the same access as senior staff managing data center infrastructure.
Finally, continuous audit readiness, including access logs, training records, and documented procedures, ensures compliance doesn’t lapse outside business hours.
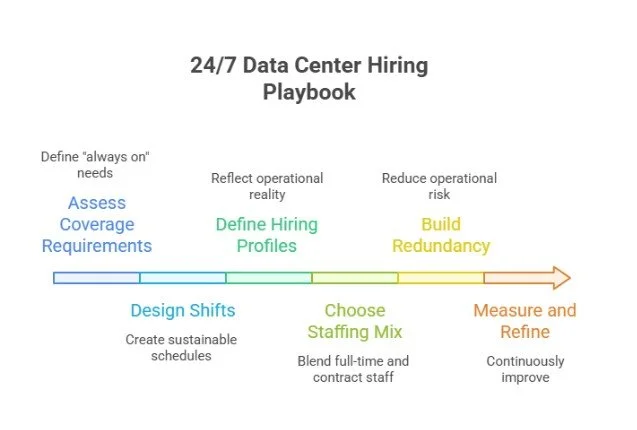
The 24/7 Hiring Playbook: Step-by-Step Summary
Here’s everything we’ve discussed so far, summarized with actionable steps:
1. Assess Coverage Requirements
Start by defining what “always on” truly means for your operation. In our experience, effective coverage requirements should reflect uptime commitments, redundancy design, and workload criticality.
Key actions:
Map critical systems (UPS systems, cooling, network) to required human oversight
Define which roles must be physically on-site vs. on call
Align staffing with RTOs and recovery point objectives (RPOs)
2. Design Shifts
Shift design translates coverage requirements into sustainable schedules. Your goal is to ensure alert, competent staffing at all times.
Whether you use 8-hour rotations or 12-hour compressed schedules, we’ve found that successful models account for fatigue, handoffs, and readiness for escalation during extended coverage periods.
Key actions:
Choose a shift model aligned to workload volatility and facility size
Limit excessive handoffs through overlap or clear documentation standards
Use workforce scheduling tools to model coverage and fatigue risk
3. Define Hiring Profiles
Hiring profiles should reflect operational reality. This includes defining correct technical and non-technical requirements based on real after-hours conditions.
What we’ve learned from supporting 24/7 environments is that candidates must be capable of independent decision-making in managing data center infrastructure, security, and redundancy after hours.
Key actions:
Define must-have skills vs. trainable skills by role
Require scenario-based interviews tied to real incidents
Clarify when senior coverage is mandatory vs. when juniors can operate independently
4. Choose Staffing Mix
Resilient teams blend full-time staff, contractors, and pipeline talent to absorb volatility caused by labor shortages and market competition.
Based on patterns we’ve observed across facilities, the right mix depends on site maturity, geographic labor conditions, and workload stability.
Key actions:
Use contractors for surge coverage and specialized tasks when necessary
Build long-term stability with full-time technicians with the help of a reliable staffing partner
5. Build Redundancy
Redundancy reduces operational risk when staff are unavailable due to illness, attrition, or emergencies, and it protects business continuity during incidents.
One consistent takeaway from high-uptime operators is that people redundancy is just as critical as power, cooling, and network redundancy.
Key actions:
Cross-train technicians across systems
Ensure multiple people can perform critical procedures
Document escalation paths for every shift
6. Measure and Refine
High-performing operators continuously measure outcomes and refine their models as workloads, technology, and risk profiles change. Metrics should connect workforce performance to operational outcomes.
Key actions:
Track incident response times by shift
Monitor overtime, attrition, and fatigue indicators
Adjust staffing models as capacity and complexity increase
Build the Dream Team with Alpha Apex Group
This playbook provides enough options to staff a data center that never stops. But doing everything on your own can be quite a challenge, especially with the talent shortage.
While you focus on big-picture items like infrastructure and expansion, we at Alpha Apex Group provide the personnel to run your facilities round-the-clock.
With our extensive reach across data center hubs (along with near-shore and off-shore talent), we can deliver both entry-level and experienced candidates for the critical roles inside a facility.
What you can expect:
43-day average time-to-fill
Shortlisted candidates delivered within 72 hours
90-day replacement guarantee
Ready to strengthen your data center workforce? Contact Alpha Apex Group today to start a focused hiring conversation and secure the talent you need—fast.
FAQs
How many technicians are required to staff a data center 24/7?
The minimum number depends on facility size, tier level, and redundancy design. As a baseline, most operators assume 4 to 5 full-time equivalents per role to sustain 24/7 coverage when accounting for PTO, sick leave, and training.
What is the best shift model for 24/7 data center operations?
There is no universal “best” model, only the best fit for your workloads and workforce. 8-hour, 3-shift rotations reduce fatigue and work well in environments with frequent handoffs. 12-hour compressed shifts (including 4-on/4-off) reduce handoffs and are common in mission-critical environments.
Should night shifts be staffed with junior or senior technicians?
Night shifts should never be junior-only, at least for critical data centers. While junior technicians can perform routine tasks, senior coverage is needed when incidents may impact power reliability, security, or uptime commitments.
Is it better to hire full-time technicians or use contractors for 24/7 coverage?
A blended staffing model, with both full-time and contract workers, is best for data centers. This is especially true at a time when data centers are faced with a skilled talent shortage and low retention.
How do you prevent burnout in 24/7 data center teams?
Burnout is one of the biggest hidden risks in always-on data center operations. Here are some practical solutions:
Predictable schedules with adequate recovery time
Fair rotation of nights and weekends
Clear escalation paths so staff aren’t carrying silent risk
Investing in workforce development and career progression
Does AAG provide long-term staffing support?
Yes, Alpha Apex Group can provide long-term staffing support, partcularly for data center facilities that require a continuous stream of skilled professionals, as well as for new entrants such as college or vocational school graduates. Besides that, we continue to support both our clients and talent even after onboarding.